




At Uniphore, we have built a fully in-house Automatic Speech Recognition (ASR) stack that continues to evolve alongside the changing demands of enterprise and customer support AI. In this blog series, we take a deep dive into how modern Automatic Speech Recognition systems are designed, evaluated, and deployed in real-world enterprise settings. In this post, we will walk through high-level ASR architectures prevalent in industry, outline the key design choices behind the current generation of Uniphore ASR, and share benchmarking results on domain-specific datasets relevant to our customers and use cases—across four languages: English, French, Italian, and Spanish, with a focus on accuracy which is the most fundamental metric for any Automatic Speech Recognition system.
Core End-to-End (E2E) ASR Architectural Families
Most modern Automatic Speech Recognition systems can be understood through three core architectural families: Connectionist Temporal Classification (CTC) [Graves et al., 2006] based models, Recurrent Neural Network – Transducers (RNN-T) [Graves, 2012], and Attention-based Encoder-Decoder (AED) models [Chorowski et al., 2015], [Bahdanau et al., 2016] which uses attention mechanism [Bahdanau et al., 2014]. Although individual implementations differ widely, these architectures capture the essential design choices around alignment (how to align audio to text), context modeling (whether output tokens are generated independently or conditioned on prior context), and latency. At a high level, all of these systems share a common encoder that transforms raw acoustic features into a sequence of higher-level representations that capture phonetic and linguistic structure, while they differ in how these representations are converted into text. CTC applies a classification head over each frame independently, RNN-T introduces a joint network that combines encoder output with a prediction network modeling output history, and AED follows the full encoder-decoder paradigm with an autoregressive decoder attending over the entire encoder output. These different decoding strategies are what drive the core tradeoffs: how the encoder output is aligned with the output token sequence, how much linguistic context dependency is modeled internally, and how well the system supports low-latency, incremental decoding.
From Continuous Speech to Discrete Tokens
Speech signals are continuous in time, while the output of an Automatic Speech Recognition system is a sequence of discrete tokens such as characters, subwords, or words. In practice, the speech signal is first converted into a sequence of acoustic feature frames, typically computed every 10 ms, resulting in hundreds of frames even for short utterances. In contrast, the corresponding transcription contains far fewer tokens.
This mismatch in sequence lengths introduces a fundamental challenge: how should acoustic frames be aligned with output tokens? For example, a single word may span dozens of acoustic frames, and speaking rates vary significantly across speakers and contexts. Directly mapping each acoustic frame to exactly one token is therefore inappropriate.
The elegant fix is the blank token, a special symbol that lets the model say “nothing new to emit here” for frames covering silence, longer-duration speech sounds (like vowels), or transitions. The blank allows the model to advance through acoustic frames without producing text, effectively decoupling the fine temporal resolution of speech from the slower rate at which tokens appear in the transcript, as shown in Figure 1.
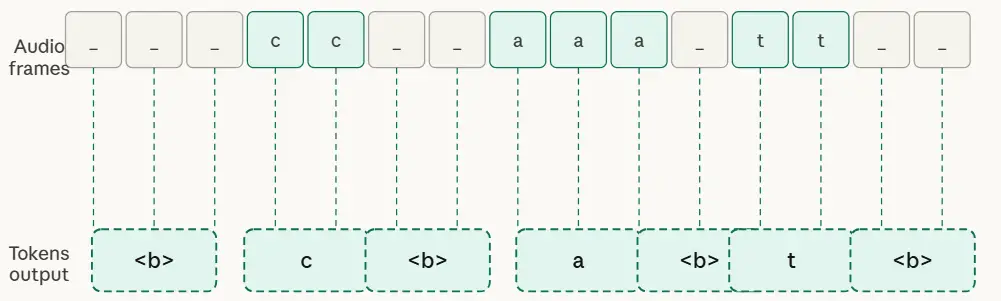
The blank token solves the length mismatch. But it doesn’t tell the whole story. Architectures still differ on two deeper questions: how strictly they enforce the order of alignment, and whether each prediction is made in isolation or informed by what was already transcribed. These two axes – alignment strategy and context modeling, are what fundamentally distinguish the three main ASR architectural families from each other.
Alignment Strategy and Context Modeling as a Defining Principle
Given the alignment problem introduced above, modern ASR architectures each propose a different answer, and the answer they choose has direct consequences for streaming capability, transcript stability, and accuracy.
Alignment refers to how the model tracks its position in the audio as it produces text: which frames map to which tokens, and in what order. Context modeling refers to whether each token prediction is informed by previously generated tokens, and if so, how much history is visible. Together, these choices strongly influence whether a model naturally supports streaming, how stable its partial hypotheses are, and how much global context it can exploit during decoding. Figure 2 shows how CTC, RNN-T, and AED each make a distinct choice on both axes [Prabhavalkar et al., 2023].
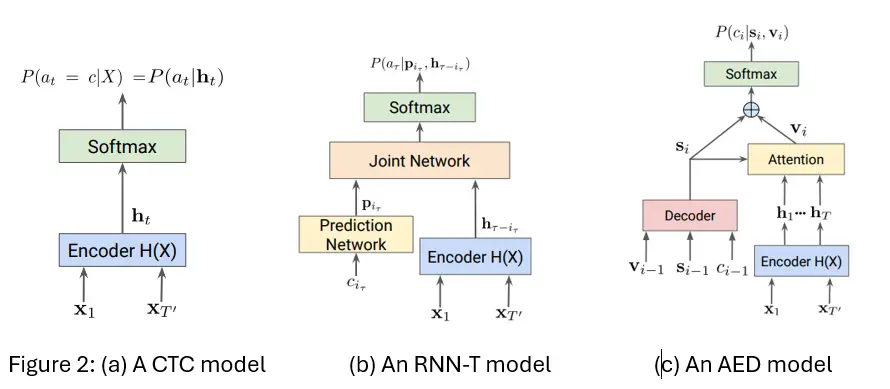
CTC takes the most direct approach to alignment, as shown in Figure 2(a). Every encoder frame, ht, independently predicts a label or a blank, and the final transcript is recovered by collapsing the sequence. The alignment is implicit, the model is never told which frame maps to which token; it discovers this through training. Because each frame prediction is fully independent of all others, CTC models have no memory of what it just transcribed when predicting the next token. For every ht, the model predictsP(at|ht). This makes CTC fast and highly parallelizable, but linguistically naive – it typically needs an external language model to produce coherent output. It remains a strong choice for high-throughput transcription where speed matters and a separate LM is acceptable overhead.
RNN-T keeps the same left-to-right alignment discipline as CTC – the model never jumps ahead or revisits past audio, but relaxes the independence assumption in a significant way. Rather than predicting one label per frame, it operates over a joint time-label space: blank transitions move forward in time, while label transitions emit a token without consuming a new frame. More importantly, each prediction is conditioned on previously emitted tokens through a dedicated prediction network, as shown in Figure 2(b). This gives RNN-T left-context modeling; the model knows what it has already transcribed, even though it cannot see ahead. The result is a system that is both streamable and linguistically aware, producing more stable and coherent partial transcripts than CTC without requiring an external language model. This combination is precisely why RNN-T has become the dominant architecture in real-time and conversational ASR deployments.
AED takes a fundamentally different approach to both axes. Rather than following a fixed left-to-right alignment path, the decoder dynamically attends over the entire encoder output at each generation step – learning soft, data-driven correspondences between audio frames and output tokens. This gives AED full bidirectional context: when generating any token, the model can draw on any part of the audio, both before and after the current position. The result is the richest linguistic modeling of the three architectures, with strong accuracy on long, complex, or noisy utterances. The cost is latency because the decoder attends over the full encoder output, the model generally needs to hear the complete utterance before producing reliable output. This makes AED the natural fit for offline transcription, batch processing, and research settings where accuracy is the priority and waiting is acceptable.
The key insight is that these tradeoffs are not incidental – they are direct consequences of the alignment and context choices each architecture makes. CTC’s efficiency comes from its independence assumption. RNN-T’s streaming stability comes from its monotonic alignment paired with left-context conditioning. AED’s accuracy ceiling comes from unconstrained attention over the full audio sequence. Understanding these root causes is more useful than memorizing benchmark numbers, because it tells us which architectural properties matter for your specific deployment.
From Architecture to Deployment: What Your Use Case Actually Demands
Understanding architectural families is useful, but in practice, ASR choices are driven less by architecture and more by application requirements. Offline transcription, real-time streaming, and conversational voice agents impose fundamentally different constraints, each favoring a different design trade-off. Offline transcription is the most forgiving: the full audio is available, latency is irrelevant, and accuracy is the primary objective. This enables bidirectional encoders, full-context attention, and computationally intensive decoding—making attention-based encoder-decoder (AED) models a natural fit. In contrast, real-time streaming systems must produce partial transcripts as audio arrives, operate under tight latency budgets, and maintain stable outputs without frequent revisions. These requirements make RNN-T the preferred architecture due to its monotonic alignment and coherent incremental decoding, while CTC remains viable in high-throughput scenarios where speed and cost are prioritized over partial stability.
Voice agents introduce an additional layer of complexity. Here, ASR is tightly coupled with dialog systems and must not only transcribe accurately and quickly but also determine when a speaker has finished—making end-of-turn detection as critical as recognition itself. Stability of partial hypotheses becomes essential, as downstream systems rely on them in real time. This pushes voice-agent ASR toward streaming architectures like RNN-T, augmented with explicit end-of-turn modeling. While traditional systems relied on silence-based endpointing, modern approaches integrate acoustic, prosodic, and semantic cues directly into the ASR model. Systems such as those from NVIDIA, AssemblyAI, and Deepgram reflect this shift, combining recognition and turn detection to achieve lower latency, more stable outputs, and behavior aligned with conversational dynamics.
How the Industry Has Converged
Given those use case requirements, it is striking how consistently the industry has landed on the same small set of architectural combinations. Despite significant differences in scale, training data, and product focus, most production Automatic Speech Recognition systems from major vendors converge on three patterns.
The first is a Conformer or FastConformer encoder paired with a CTC decoder for efficient, high-throughput transcription. The Conformer architecture [Gulati et al., 2020], which combines convolutional layers for local acoustic modeling with self-attention for long-range context, has become the dominant encoder choice across the industry, largely replacing earlier LSTM-based designs. CTC decoding on top of a strong Conformer encoder produces fast, parallelizable inference well suited to batch workloads and cost-sensitive deployments.
The second pattern is a Conformer-family encoder paired with an RNN-T or other transducer decoder for streaming and conversational applications. This combination threads the needle between streaming compatibility and linguistic coherence, and it appears across nearly every major vendor’s real-time offering. NVIDIA’s Parakeet models follow this pattern, using FastConformer encoders with RNN-T and Token Duration Transducer (TDT) decoders optimized for low-latency inference [Rekesh et al., 2023]. AssemblyAI’s Universal Streaming model pairs a Conformer encoder with an RNN-T decoder. Google’s Universal Speech Model uses a Conformer encoder with CTC and RNN-T decoding. Deepgram’s streaming models similarly rely on transducer-style architectures under the hood. Zipformer is the successor to Conformer. It recognizes that middle layers of a network don’t need high-resolution audio. It zips (downsamples) the audio in the middle and unzips it at the end, thus saving a substantial amount of computation [Yao et al., 2023].
The third pattern is an attention-based encoder–decoder for offline, high-accuracy transcription. OpenAI’s Whisper family is the most prominent example of an attention-based encoder–decoder trained on large-scale multilingual data, designed for full-context offline transcription rather than streaming. NVIDIA’s Canary models follow a similar philosophy, using FastConformer encoders with Transformer decoders for multilingual transcription and speech translation. These systems prioritize accuracy and language coverage over latency, and are the natural choice for post-call analytics, media processing, and any workload where waiting for the full audio is acceptable.
Across all of these, one pattern stands out: the encoder design sets the representational ceiling while alignment and decoding determine how effectively that representation is used. Architectures that maximize global context and expressive power tend to incur higher decoding latency, while architectures optimized for fast, incremental decoding often sacrifice some linguistic modeling capacity.
It is worth noting that in practice, the capabilities that most influence perceived system quality often have nothing to do with the core architecture. Production Automatic Speech Recognition systems layer numerous auxiliary features on top of the recognition engine – punctuation and capitalization restoration, inverse text normalization, domain-specific vocabulary biasing, keyword boosting, speaker diarization, and code-switching support. Some vendors integrate these through multitask learning within the core model; others implement them as separate downstream modules. For buyers evaluating vendors, these auxiliary capabilities frequently matter as much as word error rate (WER) benchmarks, particularly in enterprise and conversational AI deployments.
Beyond Classical ASR: Speech-Native Language Models
A newer category of system is beginning to reshape what ASR means in the context of AI applications. Models such as Microsoft’s Phi-4 multimodal, Google’s Gemini Flash Live, GPT-4o Realtime, and AssemblyAI’s Universal-3 Pro go beyond the classical transcription paradigm entirely. Rather than treating speech recognition as a standalone task, these systems integrate speech understanding, language modeling, and response generation within a single unified architecture. They support natural language prompting, instruction-following, and conversational reasoning directly from speech input – capabilities that classical CTC or transducer systems were never designed to provide.
These systems differ from streaming ASR in three fundamental ways. First, they are not optimized for deterministic, low-latency transcription – their strength is flexible, instruction-guided understanding rather than fast word-for-word output. Second, they blur the boundary between recognition and comprehension, making them better suited to tasks where the goal is extracting meaning rather than producing a verbatim transcript. Third, they introduce new trade-offs around cost, latency, and output variability that classical Automatic Speech Recognition systems don’t have.
For most real-time and conversational deployments today, classical streaming ASR remains the practical choice. But speech-native large language models (LLMs) are expanding the design space rapidly, and the boundary between recognition and language understanding will continue to blur as these systems mature.
Uniphore’s ASR Design Choices
Uniphore builds Automatic Speech Recognition systems as tightly integrated components within conversational AI platforms – not as standalone research artifacts. That product orientation is the lens through which every architectural decision is made.
For real-time and conversational workloads, such as those run on Uniphore’s Self-Service Agent and Real-time Guidance Agent, Uniphore uses streaming models built on Zipformer encoders with RNN-T objectives [Sharma et al., 2026] [Anandh et al., 2025]. The choice is deliberate: Zipformer’s adaptive computation allocation gives precise latency control in production, while RNN-T’s monotonic alignment and context modeling produces the partial hypothesis stability that conversational applications require. Generic streaming accuracy on open-domain benchmarks matters less than consistent, predictable behavior on the domain-specific conversational audio that Uniphore’s customers actually process. This is driven by a pseudo-labeling pipeline that leverages multi-ASR fusion, SpeechLLM-based correction, and domain-aware data selection to continuously improve training data quality [Rangappa et al., 2025] [Carofilis et al., 2025] [Prakash et al., 2025].
Endpointing is treated as a first-class capability rather than a downstream afterthought. Uniphore’s voice-agent models integrate end-of-turn detection directly, using both acoustic and prosodic cues (such as intonation) from the speech signal to distinguish a natural pause from a completed turn. This keeps latency low and prevents the premature cutoffs that silence-only detection systems routinely produce. A deeper dive into our endpointing design and modeling choices will be covered in a separate post in this series.
For non-real-time workloads, Uniphore supports offline ASR models that leverage full-context decoding without latency constraints, where accuracy on long-form conversational audio is the primary objective. Post-call analytics and quality monitoring (via Conversation Insights Agent) are examples of such workloads. Multilingual support, handling of code-switching by bilingual speakers, and domain-specific word boosting are built into the architecture for production-ready conversational AI system to deliver good customer experiences.
Complementing the classical ASR pipeline, Uniphore has fine-tuned speechLLMs including Microsoft’s Phi-4 multimodal architecture as a speech-language model. This enables instruction-based transcription, extraction of paralinguistic attributes (such as emotion), and higher-level conversational signal detection directly from speech (slot filling, intents, summary etc) – capabilities that sit beyond what any classical Automatic Speech Recognition system can provide [Hacioglu et al., 2026], [Watanabe et al., 2026], [Hacioglu et al., 2025] [Prakash et al., 2025] .
Putting It to the Test
The design choices described above are not made in a vacuum — they are made against a competitive landscape where every vendor is optimizing for similar goals. The natural question is: how do these systems actually compare when evaluated on the same audio? Answering that question fairly requires some care.
An important consideration is domain/industry. Automatic Speech Recognition systems trained predominantly on broadcast speech or read audio often show strong performance on standard benchmarks but degrade on real conversational audio in business use case — the kind with overlapping speech, varied accents, spontaneous disfluencies, and telephone-quality acoustics at 8 kHz. The datasets used here are deliberately chosen to reflect that reality. Performance on highly heterogeneous open-domain benchmarks will vary depending on each system’s training distribution, and some of that variation is visible in the results.
With those caveats established, the tables below compare Uniphore’s streaming models against leading third-party systems across English, French, Italian, and Spanish — covering both standard and regional accent variants. The results reflect what matters most in the deployments Uniphore is built for: accurate, stable transcription of real conversational audio, across languages, at production latency.
Before presenting the results, we note differences in training data and model scale across systems. Uniphore’s models are trained on domain-specific conversational audio using curated and pseudo-labeled pipelines totaling to maximum of around 15K hours and are of 60 to 150 million parameters in size, while systems such as Deepgram Nova-3 and NVIDIA Parakeet are trained on large-scale web, broadcast, and proprietary datasets, with model sizes ranging from hundreds of millions to billions of parameters. All evaluation datasets are strictly held-out and not used in Uniphore training. Harper Valley is an open source conversational data while Defined AI and Wow AI datasets consist of procured conversational audio reflecting real-world conditions.
Table: WER Comparison with 3P streaming models (English)
| Testset | Duration (hrs) | Uniphore (%) | Deepgram Nova-3 (%) | Nvidia Parakeet (%) |
|---|---|---|---|---|
| Defined AI (British English) | 5.07 | 10.63 | 11.40 | 8.34 |
| Defined AI (Filipino English) | 4.48 | 11.13 | 13.09 | 14.59 |
| Defined AI (Indian English) | 5.08 | 10.47 | 11.60 | 15.26 |
| Defined AI (Australian English) | 4.84 | 7.86 | 9.40 | 8.89 |
| Wow AI | 5.31 | 12.29 | 13.90 | 15.68 |
| Harper Valley | 6.59 | 8.53 | 9.40 | 18.50 |
Table: WER Comparison with 3P streaming models (French)
| Testset | Duration (hrs) | Uniphore (%) | Deepgram Nova-3 (%) | Nvidia Parakeet (%) |
|---|---|---|---|---|
| Defined AI (Canadian French) | 4.07 | 12.56 | 14.33 | 20.05 |
| Defined (European French) | 4.08 | 5.78 | 8.02 | 9.50 |
| Commonvoice | 6.52 | 37.18 | 37.27 | 37.00 |
Table: WER Comparison with 3P streaming models (Italian)
| Testset | Duration (hrs) | Uniphore (%) | Deepgram Nova-3 (%) | Nvidia Parakeet (%) |
|---|---|---|---|---|
| Defined | 4.01 | 6.24 | 10.44 | 13.10 |
| Common-Voice | 4.02 | 7.50 | 10.38 | 18.06 |
| Librispeech | 5.27 | 9.88 | 15.96 | 28.48 |
| Voxpopuli | 2.61 | 10.10 | 9.77 | 48.70 |
Table: WER Comparison with 3P streaming models (Spanish)
| Testset | Duration (hrs) | Uniphore (%) | Deepgram Nova-3 (%) | Nvidia Parakeet (%) |
|---|---|---|---|---|
| Spanish (Mexican) | 4.08 | 9.04 | 11.71 | 12.78 |
| Spanish (European) | 4.19 | 7.90 | 10.63 | 10.74 |
The results show that within the streaming regime, Uniphore’s Zipformer–RNN-T models demonstrate competitive accuracy consistently with leading transducer-based systems in the industry. Given the focus on conversational AI applications, accuracy gains are most pronounced in domain-aligned conversational data. Performance on highly heterogeneous, open-domain benchmarks may vary depending on domain exposure and training distribution, rather than architectural capability.
Conclusion
Despite the diversity of vendor offerings and research innovations, modern Automatic Speech Recognition systems are built on a surprisingly small set of architectural principles shaped by alignment modeling, encoder design, and latency constraints. Streaming transducer systems dominate conversational deployments, attention-based models excel in offline transcription, and speech-native LLMs are expanding the boundary between recognition and language understanding. As conversational AI continues to evolve, the distinction between ASR, end pointing, and language modeling will be blurred increasingly. Understanding the architectural trade-offs behind these systems remains essential for evaluating performance, selecting appropriate models, and designing voice-first applications at scale.
References
- A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,” Proc. ICML, Pittsburgh, PA, June 2006, pp. 369–376.
- Graves, A. (2012). Sequence Transduction with Recurrent Neural Networks. arXiv:1211.3711. Sequence Transduction with Recurrent Neural Networks
- Chorowski, J. K., Bahdanau, D., Serdyuk, D., Cho, K., & Bengio, Y. (2015). Attention-Based Models for Speech Recognition. Proc. NeurIPS 2015. https://papers.nips.cc/paper/2015/hash/attention-based-models-for-speech-recognition
- Bahdanau, D., Chorowski, J., Serdyuk, D., Brakel, P., & Bengio, Y. (2016). End-to-End Attention-Based Large Vocabulary Speech Recognition. Proc. ICASSP 2016. https://ieeexplore.ieee.org/document/7472621
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473. Neural Machine Translation by Jointly Learning to Align and Translate
- Prabhavalkar, R., Hori, T., Sainath, T. N., Schluter, R., & Watanabe, S. (2023). End-to-End Speech Recognition: A Survey. IEEE / arXiv. DRAGON: Determining Regulatory Associations using Graphical models…
- Gulati, A., Qin, J., Chiu, C.-C., Parmar, N., Zhang, Y., Yu, J., Han, W., Wang, S., Zhang, Z., Wu, Y., & Pang, R. (2020). Conformer: Convolution-augmented Transformer for Speech Recognition. arXiv:2005.08100. Conformer: Convolution-augmented Transformer for Speech Recognition
- Rekesh, D., Koluguri, N. R., Kriman, S., Majumdar, S., Noroozi, V., Huang, H., Hrinchuk, O., Puvvada, K., Kumar, A., Balam, J., & Ginsburg, B. (2023). Fast Conformer with Linearly Scalable Attention for Efficient Speech Recognition. arXiv:2305.05084. Fast Conformer with Linearly Scalable Attention for Efficient…
- Yao, Z., Guo, L., Yang, X., Kang, W., Kuang, F., Yang, Y., Jin, Z., Lin, L., & Povey, D. (2023). Zipformer: A Faster and Better Encoder for Automatic Speech Recognition. arXiv:2310.11230. Zipformer: A faster and better encoder for automatic speech recognition
- Sharma, Bidisha & Pandia, Karthik & Venkatesan, Shankar & Prakash, Jeena & Kumar, Shashi & Chetlur, Malolan & Stolcke, Andreas. (2025). Unifying Streaming and Non-streaming Zipformer-based ASR. https://aclanthology.org/2025.acl-industry.87.pdf
- Rangappa, P., Zuluaga-Gomez, J., Madikeri, S. R., Carofilis, A., Prakash, J. J., Burdisso, S., Kumar, S., Villatoro-Tello, E., Nigmatulina, I., Motlícek, P., Pandia, K., & Ganapathiraju, A. (2025). Speech Data Selection for Efficient ASR Fine-Tuning using Domain Classifier and Pseudo-Label Filtering. Proceedings of IEEE ICASSP 2025, pp. 1–5. https://www.isca-archive.org/interspeech_2025/rangappa25_interspeech.pdf
- Carofilis, A., Rangappa, P., Madikeri, S. R., Kumar, S., Burdisso, S., Prakash, J. J., Villatoro-Tello, E., Motlícek, P., Sharma, B., Hacioglu, K., Venkatesan, S., Vyas, S., & Stolcke, A. (2025). Better Semi-supervised Learning for Multi-domain ASR Through Incremental Retraining and Data Filtering. Proceedings of INTERSPEECH 2025. https://www.isca-archive.org/interspeech_2025/carofilis25_interspeech.pdf
- Hacioglu, K., Manjunath, K. E., & Stolcke, A. (2026). Slot Filling as a Reasoning Task for SpeechLLMs. Accepted to IEEE ICASSP 2026.
- Watanabe, H., Burdisso, S., Villatoro, E., Kumar, S., Baroudi, S., Manjunath, K. E., Roux, T., Hacioglu, K., Motlicek, P., & Stolcke, A. (2026). From Generative to Discriminative: Lightweight Adaptation of SpeechLLMs for Multimodal Emotion Recognition. Submitted to Interspeech 2026.
- Hacioglu, K., E, M. K., & Stolcke, A. (2025). SpeechLLMs for Large-scale Contextualized Zero-shot Slot Filling. Proceedings of the EMNLP 2025 Industry Track, Suzhou, China, pp. 703–715. Association for Computational Linguistics. SpeechLLMs for Large-scale Contextualized Zero-shot Slot Filling
- Prakash, J. J., Kumar, B., Hacioglu, K., Sharma, B., Gopalan, S., Chetlur, M., Venkatesan, S., & Stolcke, A. (2025). Better Pseudo-labeling with Multi-ASR Fusion and Error Correction by SpeechLLM. Proceedings of INTERSPEECH 2025. https://www.isca-archive.org/interspeech_2025/prakash25_interspeech.pdf
- AI Training Data Platform for Enterprise AI | Defined.ai
- Wow AI’s Custom Data for AI training
- HarperValleyBank: A Domain-Specific Spoken Dialog Corpus