

Research Paper: WARC-Bench: Web Archive Based Benchmark for GUI Subtask Executions, Accepted in ICLR 2026
Key Innovation: Introduces a novel GUI benchmark that poses a challenge to frontier models. We also show how state-of-the-art RLVR training techniques can unlock frontier-level performance in compact 7B and 72B models
The Cost-Accuracy Revolution
Traditional wisdom in AI development suggests that tackling complex tasks requires massive models with hundreds of billions of parameters. These behemoths deliver impressive results but come with substantial costs in computational resources, inference latency, and deployment complexity. Our work challenges this narrative by demonstrating that using SLMs for solving the right problem, along with the right training approach, can allow SLMs to compete with—and in some cases outperform—much larger alternatives. To show this, we develop a brand-new GUI navigation benchmark – WARC-Bench.
Introducing WARC-Bench: A New Standard for GUI Subtasks
WARC-Bench is a comprehensive benchmark featuring 438 carefully designed tasks that evaluate AI agents on GUI subtasks—short-horizon interactions with user interface components – that form the building blocks of complex web automation. Subtasks include actions like selecting dates in a calendar picker, navigating dropdown menus, scrolling through containers to extract information, or filling out multi-step forms. We use web archive files, which are high-fidelity snapshots of real websites as interactive environments for our benchmark.
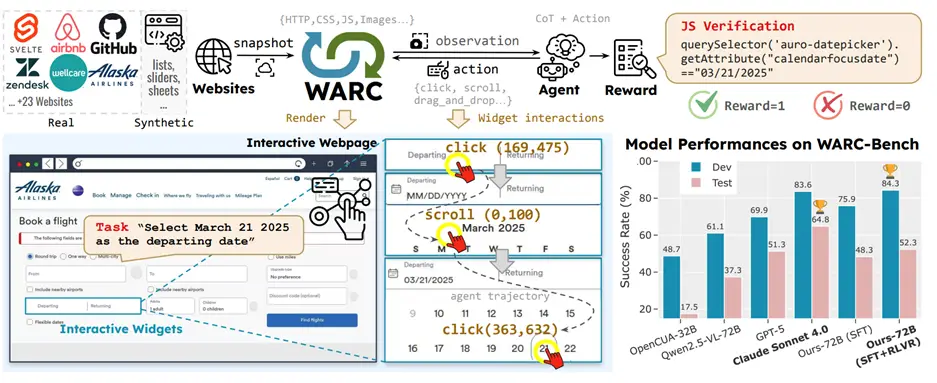
WARC-Bench tackles the following problems when compared to other GUI benchmarks:
- Real-world complexity: Uses Web Archive (WARC) files to create sandboxed, interactive environments with realistic websites including GitHub, Zendesk, Google Earth, and custom-built synthetic pages
- Programmatic evaluation: Automatic verification through reward functions eliminates subjective assessment of task completion
- Subtask focus: Targets the critical middle layer between basic UI actions and full task completion—a capability gap in existing benchmarks like MiniWob++[1], WebArena[2], OSWorld[3] etc.
- Dynamic interactions: Evaluates agents on real-time manipulation of complex UI widgets, not just static visual understanding, which is a capability gap in benchmarks like Mind2Web[4], OmniAct[5] etc.
Even the most advanced frontier models find WARC-Bench challenging. Claude Sonnet 4.0 achieves the highest success rate at 64.8%, while OpenAI’s GPT-5 scores 51.33%, leaving substantial room for improvement and demonstrating the benchmark’s ability to differentiate capabilities at the cutting edge.
The Power of Small Models: ActIO-UI Model Family
We trained ActIO-UI models in two sizes—7B and 72B parameters—using the base Qwen2.5-VL models with Supervised Finetuning and Reinforcement Learning. We present the results on two splits of the benchmark – development and test splits. The development set was used to analyze erroneous behaviors of trained models to guide hyperparameter search, while the test set is completely held out.
| Model | Parameters | WARC-Bench Dev Success Rate | WARC-Bench Test Success Rate | Deployment Profile |
|---|---|---|---|---|
| Claude Sonnet 4.0 | unknown | 83.61% | 64.8% | API-only, high cost |
| GPT5 | unknown | 69.89% | 51.3% | API-only, high cost |
| Base Qwen2.5-VL-7B | 7B | 15.54% | 4.7% | Standard GPU (16GB VRAM), low cost |
| ActIO-UI-7B-SFT | 7B | 66.54% | 27.3% | Standard GPU (16GB VRAM), low cost |
| ActIO-UI-7B-RLVR | 7B | 72.13% | 29.17% | Standard GPU (16GB VRAM), low cost |
| Base Qwen2.5-VL-72B | 72B | 61.66% | 37.3% | Multi-GPU setup, medium cost |
| ActIO-UI-72B-SFT | 72B | 75.88% | 48.3% | Multi-GPU setup medium cost |
| ActIO-UI-72B-RLVR | 72B | 84.31% | 52.8% | Multi-GPU setup medium cost |
For most practical applications, the 7B variant represents the optimal balance between capability and accessibility due to being deployable on standard hardware with just 16GB of VRAM. Organizations can run these models on commodity hardware rather than requiring expensive multi-GPU server configurations.
RLVR: The Secret Weapon for Small Model Excellence
Our models’ strong performance is based on Reinforcement Learning with Verifiable Rewards (RLVR), a training technique that has proven effective for developing reasoning-capable AI systems. Unlike traditional supervised learning that requires expensive human annotations, RLVR uses automatically verifiable outcomes to guide model improvement.
How RLVR Works
- Verifiable Outcomes: For GUI tasks, we can deterministically verify whether an agent successfully completed a subtask (e.g., did the correct date get selected? did the form submit properly?)
- Exploration and Learning: The model explores different interaction strategies and receives immediate feedback based on task completion
- Iterative Refinement: Through repeated trials, the model learns optimal strategies without requiring human labelers to evaluate every attempt
- Synthetic Data Scaling: RLVR enables training on large-scale synthetic environments, dramatically expanding the diversity of scenarios the model encounters
Beyond Parameter Count: What Really Drives Performance
Our research reveals several crucial insights about what makes smaller models competitive with larger alternatives:
1. Task Specialization Enables Efficiency
By focusing our models specifically on GUI subtasks rather than trying to be generalists, we achieve exceptional performance in our target domain. This specialization allows smaller models to allocate their capacity efficiently.
2. Two Stage State-of-the-Art Training Pipeline
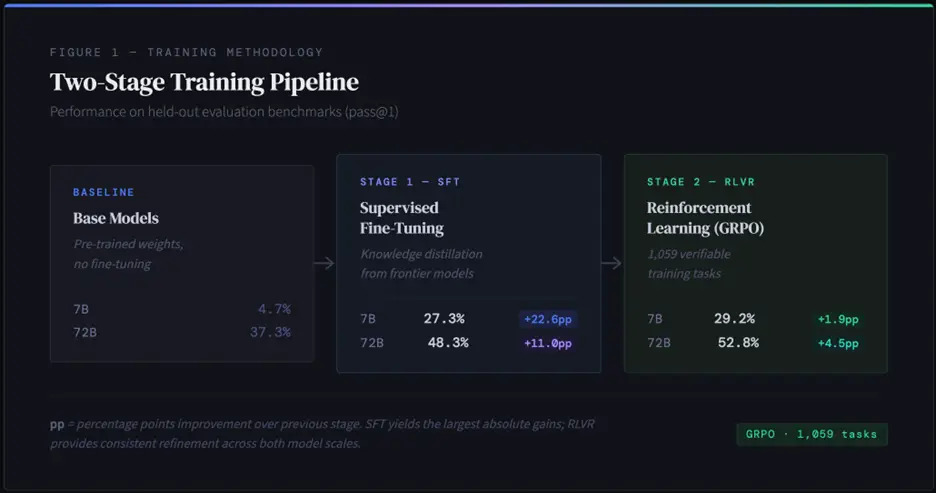
Our success stems from a carefully orchestrated two-stage training approach that combines the strengths of multiple techniques:
Stage 1: Supervised Fine-Tuning (SFT)
- 7B model: 4.67% → 27.33% success rate
- 72B model: 37.33% → 48.33% success rate
Stage 2: RLVR Enhancement
- Enhanced visual grounding: Greater precision in identifying small interface elements like calendar dates and nested menu items
- Better exploration: Increased use of scrolling actions and improved contextual awareness
- Improved efficiency: Fewer overall actions, reduced redundant clicks, and more direct paths to task completion
- Dynamic task mastery: Substantial gains in form filling, menu navigation, table manipulation, and date picker interactions
Real-World Deployment Advantages
The practical benefits of our SLM approach extend far beyond benchmark scores:
Cost Efficiency
- Infrastructure: 7B models run on consumer-grade GPUs ($500-2000 hardware) vs. enterprise server requirements for 200B+ models ($50,000+)
- Inference cost: 7x relative cost vs. 70x+ for frontier-scale models—a 10x+ operational savings
- Energy consumption: Dramatically lower power requirements enable green AI deployment
Latency and User Experience
- Response time: ~250ms for 7B models vs. 2.5s+ for 70B+ models—critical for interactive applications like GUI or voice agents
- Throughput: Higher tokens per second enables better user experiences in production
- Real-time interaction: Low latency makes GUI automation feel natural and responsive
Operational Flexibility
- On-premise deployment: Smaller models enable air-gapped, secure environments without cloud dependencies
- Edge computing: Deploy closer to end users for lower latency and better data privacy
- Easier maintenance: Simpler model serving infrastructure reduces operational complexity
Conclusion: Smarter Training Beats Bigger Models
WARC-Bench and our ActIO-UI models demonstrate that with state-of-the-art training techniques like RLVR, small language models can achieve frontier-level performance at a fraction of the cost.
The future of AI isn’t just about scale; it’s about smart specialization, innovative training methods, and finding the optimal balance between capability and practicality. As we continue to refine RLVR techniques and expand WARC-Bench with more diverse tasks, we’re excited to see how the community pushes these boundaries further. The era of accessible, high-performance AI automation has arrived, and it’s smaller than we think.
Learn More:
- Read the full paper: WARC-Bench: Web Archive Based Benchmark for GUI Subtask Executions
- Access our models: ActIO-UI-7B-SFT on Hugging Face
- Explore the benchmark: WARC-Bench
For inquiries, contact the research team at Uniphore.