

Voice agents for enterprise require safety guarantees at multiple points in the agentic workflow, not only when generating the final response that a user hears. This post describes a multi-layer guardrail architecture applied at three checkpoints: user input, tool call execution, and agent output. At each checkpoint, different combinations of content safety, jailbreak detection, topic adherence, and factuality checks apply, governed by what is meaningful and feasible to check at that stage. A central design challenge is latency: we show how parallel execution of guardrails and LLM inference keeps safety checks off the critical path for user input, how a mix of deterministic and model-based validation handles tool calls with minimal overhead, and why streaming output remains the hardest problem, with buffering, sliding windows, and token-level classification each carrying significant trade-offs.
Types of Guardrails in Agentic Systems
Voice agent systems are increasingly common in the traditional customer service domain. In addition, voice agents are gaining traction in healthcare and legal applications. All applications of voice agents require guardrails on the inputs and outputs to the system, but especially those applications which make financial, health, or legal decisions. Guardrails consist of multiple kinds of checks: content safety checks, topic adherence checks, and jailbreak checks. These checks are used in different combinations at various points in an agentic workflow.
Content Safety
Content safety checks determine whether the user or large language model (LLM) generated harmful, offensive, or inappropriate content. It also classifies such content by type: violence, sexual content, criminal planning and confessions, guns and illegal weapons, controlled and regulated substances, suicide and self-harm, hate and identity-based hate, personally identifiable information (PII) and privacy, harassment, threats, and profanity. These unsafe content classes encompass the full scope of unsafe speech and are based on Appendix A.12.3 of the AEGIS2.0 paper (https://arxiv.org/pdf/2501.09004).
Topic adherence
Voice agents for enterprise use cases are typically designed to handle well-defined use cases. Topic adherence checks determine whether a user’s request falls within the scope of the intended use case
Jailbreak attempts
Jailbreak checks flag utterances that constitute a jailbreaking prompt. A jailbreaking prompt is an input to an LLM that makes the LLM generate content that is outside its intended use case. Such out-of-scope uses include generating unsafe content, but also anything which falls out of the intended use case for the voice agent. For example, an attempt to jailbreak the voice agent so that it functions as a calculator, while not unsafe, may nevertheless be an unintended use case for a voice agent in a customer service domain. Our approach to the problem is based on the datasets in Improved Large Language Model Jailbreak Detection via Pretrained Embeddings.
Factuality
Factuality checks determine whether an LLM has generated a response that is grounded in truth. The source of truth may be either the conversation history (i.e., the log of all previous utterances in the conversation) or an external knowledge base (e.g., a set of company documents). Factuality checks apply not only to the natural language responses that the text-to-speech (TTS) system speaks out to the user, but also to internal generations of the LLM, such as tool calls. Factuality is checked using Provenance framework (https://arxiv.org/abs/2411.01022)
In this blog post, we describe how these various guardrails integrate into a voice agent framework, where low latency and streaming are essential for a natural user experience. We’ll examine how guardrails apply at three points in the agentic workflow: first as a check on user input, then as checks on tool calls, and finally as a check on agent output.
Guardrail Checkpoints in Agentic Systems
Specific guardrails are invoked at different points in an agentic system. In a single turn of an agentic interaction, requests are made to the LLM, which generates a sequence of tool calls before generating a final answer, which it streams back to the user. This processing is done in parallel with guardrails. The diagram below illustrates how the guardrails are coordinated with the LLM and tool execution for an example turn in an agentic workflow, in which the LLM first generates and executes one tool call, then uses the output to generate a response.
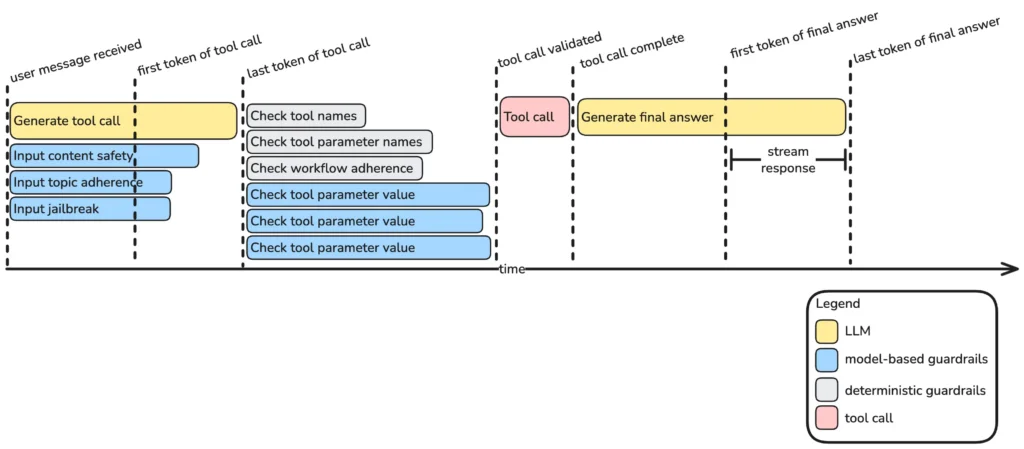
The following sections describe the processing that occurs at each step: how the user input is validated in parallel with the LLM request; how the tool call is then validated before the tool is executed; and how the answer then gets streamed back to the user. Alternatively, if the output is not streaming, output safety validation may then follow prior to returning the response.
User Input Validation
When a user speaks to a voice agent, their utterance is transcribed and must then be checked before the LLM takes any action. This is our first guardrail checkpoint, where we check user content safety, user topic adherence, and jailbreaking. Factuality is not applicable at this stage because users typically provide personal information, reasons for calling, objections, details, or personal preferences that are not factually verifiable with respect to any external data source.
If latency was not a concern, guardrails would execute before the LLM began processing any prompt. However, blocking the LLM introduces unnecessary latency. The guardrails do not need to block the request to the LLM, but rather need only block the LLM from taking any action: either executing a tool call or responding to the user.
Accordingly, the agentic framework makes requests to the guardrails service simultaneously with the request to the LLM. The LLM processes the prompt and then starts generating tokens, starting with thinking tokens. Depending on the thinking strategy, these thinking tokens may constitute planning, reasoning, or reflection. The LLM generates these thinking tokens at the same time the guardrails are checking the user input. Once these thinking tokens are generated, the LLM then proceeds to generate either a tool call or a final answer. The LLM may generate the tool name, the parameters, and the parameter values all while the guardrails are executing. Additionally, the agentic framework may even validate the tool call while the input guardrails execute. However, the tool call may not be executed until the guradrails check completes. The final answer is the agent’s response to the user, which must be stored in a buffer until the guardrails checks complete. Only after the guardrails complete can the tool executor execute a tool call or the TTS process the final answer.
The choice of model for input guardrail checks involves a fundamental trade-off between accuracy and latency. Because these checks execute in parallel with the LLM’s thinking tokens, they must complete before the LLM finishes that generation phase, otherwise they land on the critical path and add noticeable lag. In practice this means targeting inference latencies under 50ms.
Large LLMs (e.g., 8B+ parameter models) can achieve high accuracy on safety classification, but incur inference latencies on the order of 600ms or more even on optimized hardware. Lightweight dedicated classifiers such as a 67M parameter DistilBERT or a 307M parameter mmBERT deliver latencies in the 40-50ms range while maintaining sufficient accuracy for binary and multi-class safety tasks. Serving these classifiers behind a REST API, as implemented in the framework’s InputSafetyGuardrail and InputJailbreakGuardrail, further allows the agentic framework to issue both checks as concurrent async requests, overlapping their latency with LLM thinking time.
When calibrating these models, it is better to err on the side of higher recall (fewer missed violations) over higher precision (fewer false positives). The cost of a false positive is low: the agent deflects a legitimate request with a clarifying message. The cost of a false negative (i.e., allowing a jailbreak prompt or unsafe content to reach the LLM) can be high. Guardrail models should therefore be tuned toward minimizing false negatives, even at the expense of occasional false alarms.
A natural question is why not simply rely on the main LLM to detect and reject unsafe inputs. Two reasons favor dedicated classifiers. First, a lightweight classifier is an order of magnitude faster, keeping the guardrail check off the critical path and preserving conversational naturalness. Second, the classifier output is symbolic (e.g., a binary flag or categorical label) rather than natural language. A boolean or enum value is trivially handled in code; a natural-language refusal from the LLM must be parsed, introduces ambiguity, and may itself require a safety check. Symbolic guardrail outputs integrate cleanly into the deterministic branching logic of the agentic framework.
The framework supports two backend engines for content safety and jailbreak detection: NeMo Guardrails (the default, using NVIDIA’s nemoguard-jailbreak-detect) and mmBERT, a multilingual BERT-based model suited for deployments that serve speakers of multiple languages. The engine is specified at guardrail construction time and passed transparently to the guardrails service API, so the calling code is engine-agnostic.
Tool Call Validation
After the LLM processes the user’s request, it generates either a tool call or a final answer. The agent must validate tool calls with respect to a number of criteria. First, we can check whether the name of the tool exists in the environment. Second, we can check whether the generated parameter names are correct. Third, we can check whether the tool call can be executed at the current conversational state, given the conversation history and a graph representation of the conversation flow. Fourth, we can check whether the generated parameter values are correct, given the conversation history.
If any of these checks fails, the agentic framework can prompt the LLM to regenerate the completion, providing it with a descriptive error message to guide the retry. After exceeding a maximum number of retries, the agent escalates to a human agent who can better assist the user.
The four levels of tool call validation have very different latency characteristics, and understanding this difference is essential for deciding how aggressively to apply each check.
Tool existence checking and parameter schema validation are purely deterministic. Tool existence is implemented as a set membership test and thus executes in microseconds. Parameter name validation is an equivalent set lookup against the tool’s declared schema. These two checks together impose negligible overhead and can always be applied unconditionally.
Workflow state validation—verifying that the tool is callable at the current conversational stage given a directed acyclic graph (DAG) representation of the conversation flow—involves graph traversal. Implemented using NetworkX, traversal is still fast in practice because agentic workflow DAGs are compact (typically tens of nodes), and dependency checking requires only iterating over a node’s parent edges. The total time for a DAG traversal is negligible on any modern hardware.
Parameter value validation is where the latency profile diverges significantly based on check type. Syntactic validation (e.g., regex pattern matching, enum membership, numeric range bounds) is fully deterministic and executes in microseconds. Semantic validation of parameter values, however, requires reasoning over the conversation history in order to verify that values are grounded in information the user previously provided or that a prior tool call returned. This may involve an additional LLM inference, adding hundreds of milliseconds. For this reason, semantic value validation is applied selectively to the most consequential parameters (e.g., account identifiers, financial amounts, medical codes) rather than uniformly across all tool arguments.
The practical result of this layered approach is that the common case (i.e., a valid tool called in the right order with syntactically correct parameters) completes in under a millisecond. Slower, model-based semantic checks are reserved for high-stakes parameter values where the cost of an incorrect tool execution justifies the added latency.
Output Safety
Before the agent’s response is converted to speech and played to the user, we perform final checks for content safety and factuality. With regard to content safety, we check the LLM’s output for:
- Inappropriate content
- Harmful advice
- Policy violations
- Sensitive information leakage
Output factuality is most important in the context of Retrieval Augmented Generation (RAG). RAG is a common tool in an agentic framework which enables agents to answer questions with respect to information from a defined knowledge base. The typical RAG setup includes retrieval, reranking, and generation. Considered as a tool in an agentic framework, only the first two steps of retrieval and reranking are executed as part of the tool call. The tool returns relevant chunks and leaves the generation of the final answer to the LLM. Factuality checks whether the final answer is consistent with information in the relevant chunks returned by the retrieval and reranker. If the factuality check fails, the agentic framework can prompt the LLM to regenerate the completion, providing it with a descriptive error message to guide the next attempt at answering the question. If, after exceeding a maximum number of retries, the agent still fails to generate a factual answer, it may escalate to a human agent who may be able to answer the user question.
The critical limitation of output safety guardrails is that they require a complete response before checking. This makes it incompatible with streaming, where TTS accepts a stream of chunks, each sent one at a time. After streaming 49 chunks to TTS, it is too late and possibly pointless to interrupt if unsafe content is detected at chunk 50.
There are three main approaches to circumvent this critical limitation, each with significant drawbacks. The simplest is buffering: the agent accumulates the complete response before releasing any chunks to TTS. This guarantees that the guardrail sees the full output, but adds 1-3 seconds of latency before the user hears anything. A second approach is a sliding window, in which the last N tokens are checked periodically as the response streams in. This reduces buffering latency but introduces two new problems: violations that span a window boundary may go undetected, and checking frequently generates a high volume of requests to the guardrails service. A third approach is token-level classification, in which each token (or small chunk) is scored independently as it is generated. This is fast and avoids buffering entirely, but individual tokens carry little context, making classification substantially less accurate than whole-response checks.
Conclusion
Building safe voice agents requires defense in depth: fast, lightweight classifiers at the user input stage; deterministic and model-based validation at the tool call stage; and content safety with factuality checks at the output stage. No single check is sufficient on its own, and no single check applies at every stage.
The central design tension is latency. Parallelism (i.e., running guardrails concurrently with LLM inference) is the primary tool for keeping safety checks off the critical path, but it has limits. Streaming output in particular remains an open problem: buffering adds latency, and sliding window approaches may miss violations that span a window boundary. This makes strong input and tool-call guardrails all the more important as the first lines of defense, since catching a problem early is always cheaper than catching it late.